Source: this review paper on segmentation and object detection methods, MobileSAM paper, TinyCLIP paper and OpenCV documentation
Visual Language Models (VLMs) are advanced multimodal AI systems that combine large language models (LLMs) with vision encoders to understand and generate insights from both visual data (like images and videos) and textual information.
I also like this explanation from the OpenCV documentation
Vision Language Models (VLMs) are AI systems that seamlessly combine image understanding with natural language processing. Unlike earlier models that handled vision and text separately, VLMs connect what they see with the words that describe it, allowing machines to “see” and “read” at the same time.
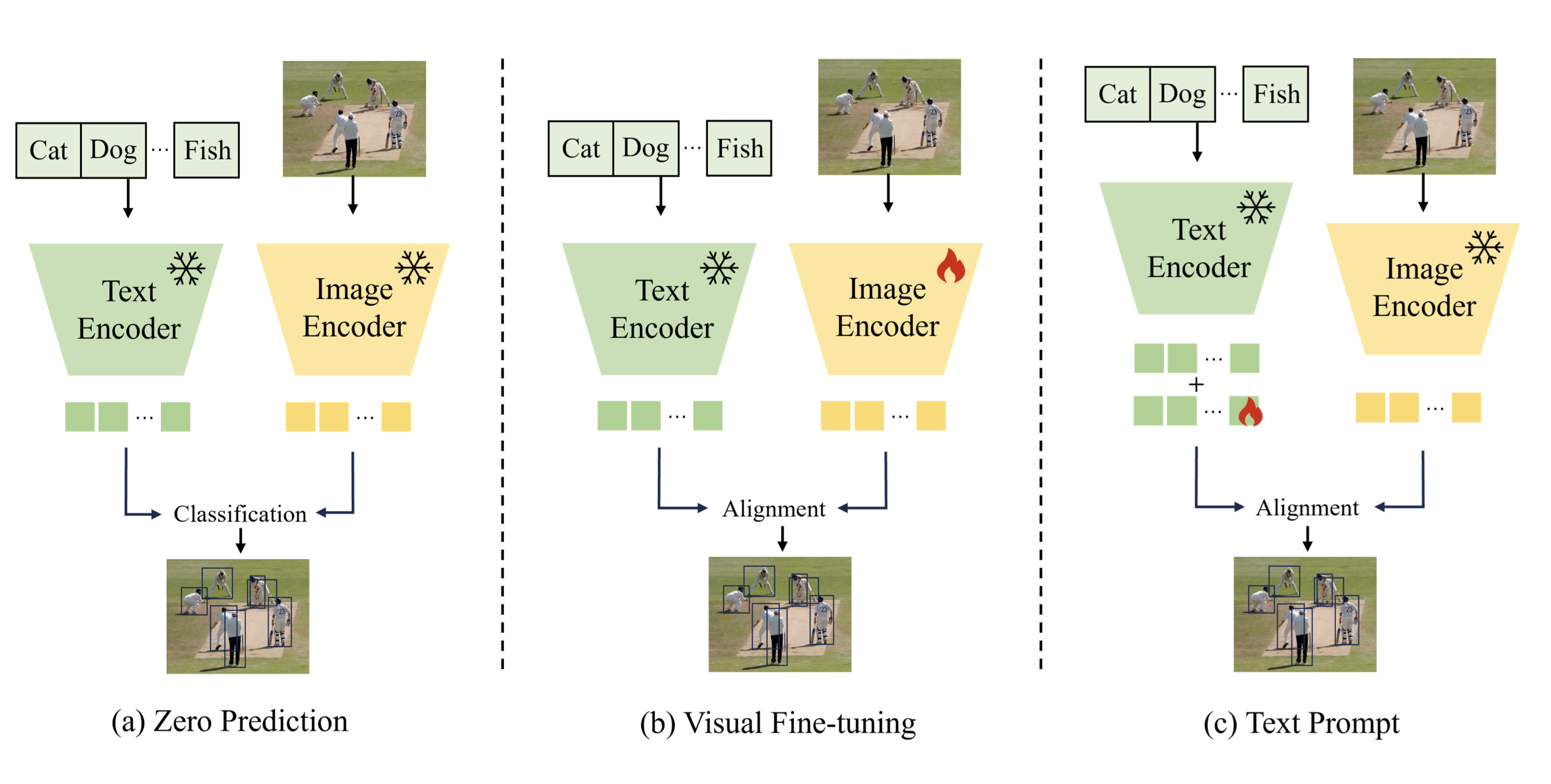
So the key components for implementing a VLM are:
- Image Encoder: Extracts meaningful features from images by dividing them into patches and processing them using a
Vision Transformer (ViT).
- Vision–Language Projector: Aligns image embeddings with text embeddings by projecting visual features into the same dimensional space, using a small multilayer perceptron (MLP).
- Tokenizer + Embedding Layer: Converts input text into token IDs and maps them to dense vectors that capture semantic meaning.
- Positional Encoding: Adds spatial or sequential information to embeddings, helping the model understand token order and context.
- Shared Embedding Space: Combines projected image tokens with text embeddings into a unified sequence, allowing joint attention over both modalities.
- Decoder-Only Language Model: Generates output text autoregressively, producing tokens one at a time based on the integrated visual-textual context.
So the main idea is that my architecture will take as input only a image and a prompt.
I have the following constraint for this task:
- I need to perform detection and localization using VLMs without using anchor-based or pre-trained detection models such as YOLO,
- Run locally on an edge device so no cloud services or APIs. Efficiency in memory and processing is key.
- Handle unseen object categories: the system must be able to generalize new objects using textual prompts and avoid reliance on fixed class labels or retraining.
- Respond to prompts such as “pick the pen” or “take the scissors”,
- Return a bounding box
My solution to this challenge
MobileSAM for the segmentation
I must make this application as lightweight as possible. As I am very passionate about Edge Computing, I did some research on possible lightweight segmentation methods and I found this paper ('Many of such applications need to be run on resource-constraint edge devices, like mobile phones. In this work, we aim to make SAM mobile-friendly by replacing the heavyweight image encoder with a lightweight one. The training can be completed on a single GPU within less than one day, and the resulting lightweight SAM is termed MobileSAM which is more than 60 times smaller yet performs on par with the original SAM.') regarding MobileSAM.
The default image encoder in the original SAM is based on ViT-H with more than 600M parameters, which is very heavyweight and makes the whole SAM pipeline incompatible with mobile devices. Therefore, the key to obtaining a mobile-friendly SAM lies in replacing the heavyweight image encoder with a lightweight one, which also automatically keeps all its functions and characteristics of the original SAM.
So they propose a method called Coupled distillation. They observed that training a SAM with ViT-H image encoder takes 68 hours on 256 A100 GPUs. Replacing the ViT-H with ViT-L or ViT-B reduces the required GPUs to 128, which is still a non-trivial burden for many researchers in the community to reproduce or improve their results. So following their approach, we can further adopt an even smaller image encoder and retrain a new SAM with their provided segmentation dataset which is 11-T.
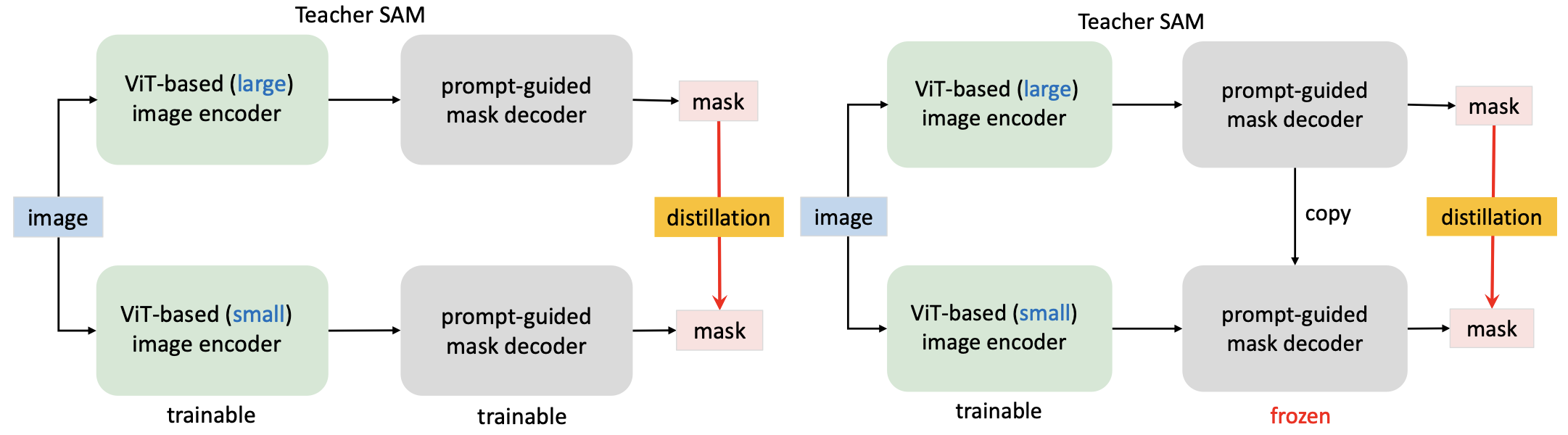

Their research states that MobileSAM is faster than FastSAM and performs on par with the original SAM. It also offers smooth CPU compatibility with ONNX export, ideal for edge devices. As a conclusion, I will go with this approach.
The implementation is available on GitHub
https://github.com/ChaoningZhang/MobileSAM
I will create a submodule in my GitHub repository linking to this one. It’s both easy to update and a clean solution.
TinyCLIP for Visual-Language Matching
This paper suggests that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. The idea is very similar to MobileSAM, as weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency.
CLIP-like language-image models commonly consist of two branches: an image encoder and a text encoder. CLIP uses 400M parameters while TinyCLIP only 63M. That’s a significant reduction(84.25%) while maintaining similar performance. The original CLIP models are pre-trained on 400 million image-text pairs for 32 epochs, taking thousands of GPU days.
I tested the following models:
wkcn/TinyCLIP-ViT-8M-16-Text-3M-YFCC15M - would return only the purple end of the marker
wkcn/TinyCLIP-ViT-61M-32-Text-29M-LAION400M - 61M for visual and 29M for text. It would return solid boxes. But for example; only the head of the screwdriver.
openai/clip-vit-base-patch32 - somewhere around ~151M parameters but when asked to return the screwdriver; it returns the scissors.
I decided to stick with the middle option as it gave the best results considering the trade-off. I would be honest and say I did not even feel the trade-off. It was simply the best option.
Results
The average running time is ~22 seconds. I am running everything inside a VM running Ubuntu so every time the device falls back to cpu.
# The best combination of VLM was
# TinyCLIP with 61M visual params and 32M text params
# MobileSAM in the following configuration
mask_gen = SamAutomaticMaskGenerator(
mobile_sam,
points_per_side=16,
pred_iou_thresh=0.8,
stability_score_thresh=0.85,
crop_n_layers=0,
min_mask_region_area=200,
)
# The following arguments for the MobileSAM solved absolutely nothing and would only increase runtime by over 400[seconds]
mask_gen = SamAutomaticMaskGenerator(
mobile_sam,
points_per_side=32,
pred_iou_thresh=0.86,
stability_score_thresh=0.92,
crop_n_layers=1,
min_mask_region_area=100,
)



